OpenClaw notes on a trustworthy system
A system that runs isn't a system I'd trust.
The moment a personal AI system is easiest to misjudge is the first moment it actually runs.
The service is up, the page opens, the agent replies, the tools fire. It's very easy to say at this point: good, system done.
But the more I work on this, the more I feel "it runs" is only the first layer. The hard part is: tomorrow, can we pick it back up; can another AI read it; when something breaks, can we run a retrospective; can I confidently hand it the next step.
So what I added afterward wasn't "swap in a smarter model" — it was a work system that lets it be checked, handed off, and recovered.

01 / The illusion of running
It can answer doesn't mean it knows what it's doing
A lot of AI systems already look like they can work: chat, write files, run scripts, call external tools.
But if it doesn't know which files are the canonical source, doesn't know which actions need to stop and confirm, doesn't know why a judgment was made last time — then it's only "running," not "trustable."
The trap I've fallen into most is taking one successful run as system capability. What you actually look at isn't whether it ran this time; it's whether it stably reproduces next time.
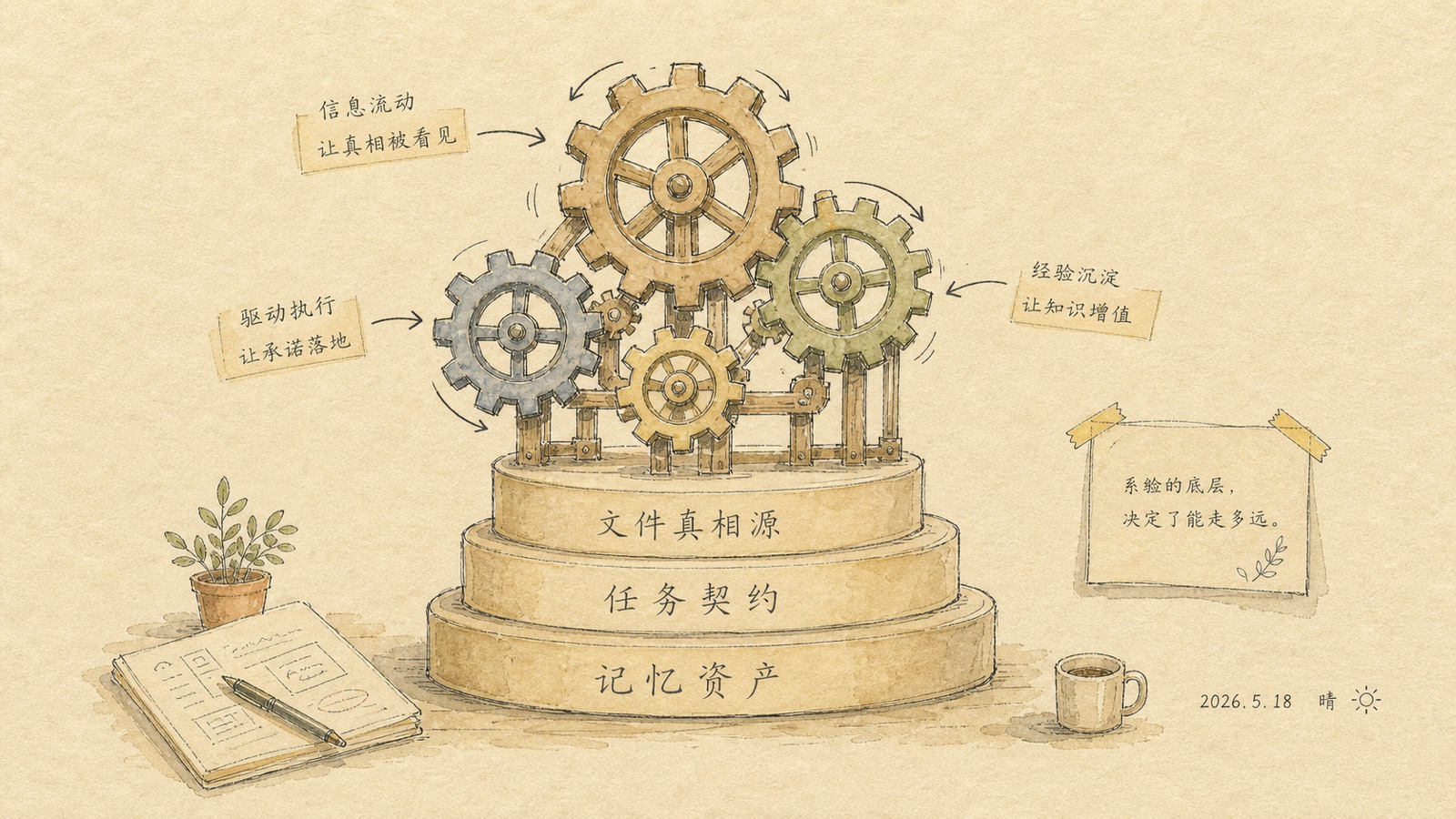
So my fix was plain: take all the things that easily scatter inside chat, and move them into checkable files, task folders, and evidence chains.

File canonical source
State can't live in chat memory — it has to land in project state files, task folders, and output folders.
Task contract
Every task spells out goal, boundary, input, output, acceptance, and stop condition.
Memory as asset
Not "remember more chat" — sediment judgments that can be searched, reused, scored, and iterated.
Evidence chain
Important conclusions trace back to source, artifact, test, screenshot, report, or retrospective.
Handoff
What today's AI finishes, tomorrow's AI — or tomorrow's me — can keep picking up.
Locally controlled
Before trust is earned, stay a local candidate; don't rush to touch real external sending or production actions.
02 / My first step
Move the canonical source out of chat and into files
A lot of state used to live in chat: where we got to, which conclusion got overturned, which file is the latest version, which action only ran once.
Now I try to compress this into real files: project state, current task, notes, outputs, handoff, verification screenshots, build logs, audit tables. Chat can move things forward — it can't monopolize the truth.
This step sounds dumb, but it's critical. As long as the canonical source still lives in chat, the system can't really hand off. As soon as it lives in files, another agent can re-enter the site.


03 / Task contracts
A task is no longer one chat request
I write complex tasks as a small contract: what to do, what not to do, what it depends on, how completion is counted.
That way the agent isn't "improvising as it goes" — it's moving inside an explicit boundary.

04 / Memory as an asset
Not "remember everything"
What I actually want isn't "it remembers everything" — it's that the key experience can be retrieved, reused, scored, and iterated.
Memory isn't a favorites folder. It has to become a work asset usable next time.
05 / Evidence, audit, handoff
Trustworthy is: someone else can run the retrospective, and tomorrow can continue
I'm less and less willing to just write "done." What I'd rather see: what sources were used, which files changed, where the artifacts live, how it was verified, where the warnings still are.
That's why I keep notes, outputs, screenshots, build results, audit conclusions, and handoff. They're not formality — they're how the system gets picked up by the next person, the next AI, the next session.
Before that point, I'd rather call it a locally controlled candidate version. It can prove direction; it doesn't equal "ready to ship," doesn't equal "ready to send externally," doesn't equal "ready to touch real transactions or production actions."
