知识库整理笔记
整理一个 AI 项目知识库的时候,最难的不是没东西可留——是「什么都想留」。
AI 项目里随便一段时间就能攒出一堆材料。聊天记录、运行日志、装机备份、agent 设定、临时报告、状态文件、scripts、evidence 截图……每一份单独看都觉得有点用,扔哪个都觉得可惜。
可一旦真把它们全部塞进一个所谓的「知识库」,几周以后回头看,它跟之前那堆「散落的工作目录」没区别。表面整理过了,本质只是把垃圾搬了一遍。
所以现在每次开始整理之前,我都会先做一件笨事:把「留什么、扔什么」写下来。一旦规则写出来,整理就是机械动作;一旦写不出来,整理就永远在犹豫。
核心矛盾:原料一直在加,时间一直在少
这个矛盾我以前一直不肯承认。心里想——先全部留着吧,反正硬盘够大,等以后再选。
可「以后再选」从来不会真的发生。知识库一旦超过几百份文件,下次进来的人——包括我自己——就不想读了。体积会反过来吓退所有人,包括作者自己。
所以「留全」看着安全,反而是最贵的选择。代价不在硬盘——硬盘买就是了——而在注意力。每多留一份意义不明的材料,下次打开就要多分一份注意力去判断。十次之后,谁都不想再开。
错误解法:留最新、留最长、留官方
早期我也偷过懒,用过几条「看起来挺合理」的筛法,全部翻了车。
- 留最新——但最新经常只是被人最后碰过,不代表上面说的事还成立。
- 留最长——但最长往往是 AI 帮我整理的总结,里面混了不该混的东西。
- 留官方——但带 FINAL / SPEC / README 的文件,很多其实是早期版本,后来被实际运行结果推翻了,只是文件名没改。
三条单独看都不蠢,三条放在一起就出事——剩下的全是「看着权威,其实早就过期的 AI 总结」。这种东西比聊天记录更危险,它装得像知识。
后来我换了个法子,分两层判。
第一层判定:这份材料能不能继续支撑工作
第一层只问一个问题:未来某一天我重新进入这个项目,要不要看这份材料?说不要就扔。说要就再追一句——是材料本身有用,还是结论已经被别处的审计报告或设计文档收走了?被收走了,原材料也不用留。
按这条线一刀切下去,材料就只剩两类。
能留下来的:能继续工作的知识
- 项目概览、架构、设计文档——知识,不是状态;告诉你系统长什么样、为什么这么搭。
- 审计结论、决策记录——定下来的判断,比过程更值钱。
- 运行方式、端口、命令面——下次想用,第一时间查这些。
- 变更日志、时间线——让人理解「为什么演变成今天这样」。
- 装机归档(每次一份)——重装系统时必然回头翻。
- 装机备份里的 audit snapshot、archive 冷存储的 knowledge 子目录、agent 训练记录里的「工程分析」——原本散在乱目录里,只要能继续支撑工作,就提出来归位。
排除掉的:运行时和工程产物
- 源代码、脚本、补丁——归 repo 管,不是知识。
- 运行日志、缓存、依赖——重新跑一次就能再生成。
- evidence、backups、raw 原始材料——过程证据,结论已经收了。
- 对话原文(kimi sessions、claude memory、codex memories)——机器的工作记忆,不是人工知识页。
- 含 token 或 secret 的运行时配置——运行时身份,不是知识。
- 身份、角色、灵魂、心跳类的设定文本——prompt 工程产物,公开既不安全也没价值。
- 装机备份里的 home 系统文件、archive 里的 books/raw/tasks、过往 AI 聊天记录——同样按属性归到这一类,不要为「这个目录还有点东西」整个保留。
这一层最容易被忽略的,是把目录拆开看。一个目录里既有要留的、也有该扔的,很正常——按属性分两堆,不要因「整理麻烦」整个搬走,也不要因「里面有几份没用」整个删掉。
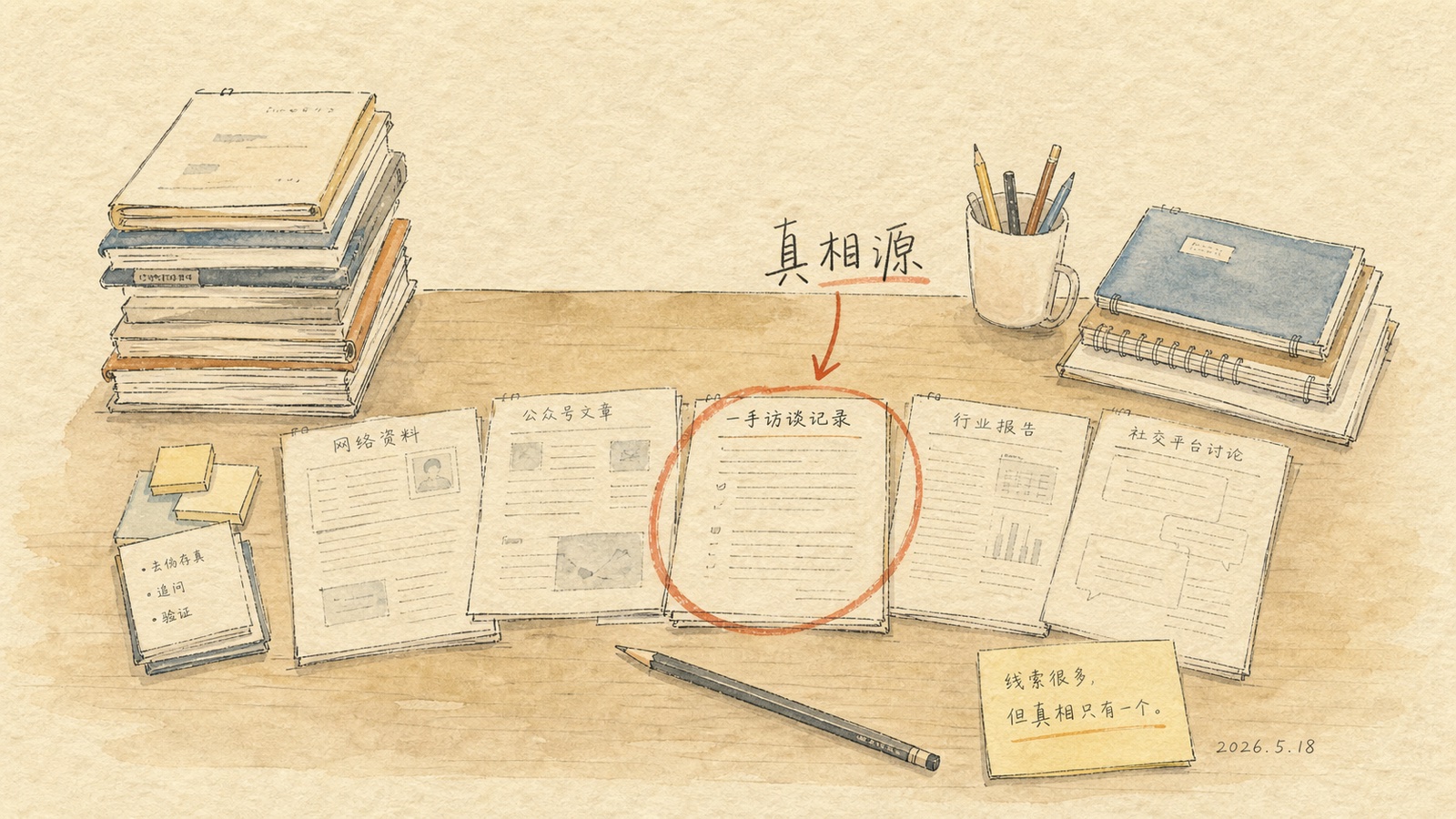
第二层判定:在多份能留的材料里,谁是真相源
第一层过滤完,麻烦才真的开始。同一个项目,可能本地有一份设计文档、archive 里也有一份;安装文档可能写到了 v3,但 v1 v2 还在;同一个状态,audit 报告里写了,运行日志里也写了。每一份都说自己对。
这种时候不能汇总——汇总只会把冲突包装得更漂亮。得有人裁判。
下面六条不是真理,是工作规则——不为挑出最好的,只为给材料固定优先级,让我下次不必从头裁判。
- 原始文件优先于备份。备份是为了应急,不是为了被引用。
- 最新稳定版本优先于旧版。注意是「稳定」,不是「最近改过的草稿」。
- 设计文档优先于运行时痕迹。命令、状态、日志告诉你它现在在做什么;spec 告诉你它本来该做什么。
- 历史账本优先于原始聊天全文。账本是压缩过的锚点,原始聊天是流水。
- 本地当前事实优先于 archive 里的重复副本。archive 是历史,不是现在。
- 涉及人设、身份、灵魂、心跳的文本,默认排除。这一类是 prompt 工程产物,不属于公共知识。
第三件事:给每一页打「新鲜度」标记
留下来的页面也会过期。不及时处理,知识库又会变成「什么都对、又什么都不一定对」的状态——和最开始那堆乱目录没两样。
所以我现在每一页都带一个新鲜度状态。三态够用,再多就没人维护:
- verified——最近被人或 AI 对照过源头,还成立。
- stale——源头已经动了,这一页可能不准,但还能当线索。
- needs review——一眼能看出冲突,必须有人重新看。
这三态不复杂,关键是给了「什么时候必须更新」的明确信号。没信号,所有页面看起来都同样可信,问题会偷偷写进下一次判断。
我自己有一条简单的线:通不过一次快速源头核对的页面,不该让人觉得权威。它可以当线索,但要降级——不能继续装成 verified。
真实结果:三个 wiki 的对照
跑完这套流程,我整理了三个规模不大、但能持续工作的 wiki:
- llm-wiki——工程知识库,存页面原则、项目状态、生态治理、审计与决策。
- openclaw-knowledge——OpenClaw 项目专门库,存安装设计、版本选择、安全加固、历史账本。
- yun-archive-wiki——个人归档库,存音乐索引、装机审计、冷存储 knowledge 部分、重装后报告。
三个库各自有「留 / 扔」表,但底层判定同一套。这比内容完不完整更重要——以后任何一个 wiki 出问题,我用同一种方法整理,不必重新发明判断。
顺带一提,它们都很小。llm-wiki 19 个 markdown、76KB;openclaw-knowledge 7 个、28KB;yun-archive 11 个、44KB。加起来不到 150KB。
这是我后来才慢慢接受的事——真正能用的知识库往往很小;大的那个通常不是知识库,是工作目录的备份。
给自己定的几条边界
这套流程能持续跑下来,靠的不是某条规则特别聪明,而是几条很笨的边界一直没破。
- 不让「以后再选」成为理由——决定不下来的,要么当时排除,要么标 needs review 进下一轮。
- 不让 AI 替我定真相源——AI 可以列候选、找重复、提冲突,但选哪一份当权威,是我的事,还要写进「留 / 扔」表里。
- 不让「看着权威」等同于「权威」——FINAL / SPEC / README 这种名字,照样要走两层判定。
- 不让原始材料和整理结果混在同一个目录——原料留在工作目录,整理结果进 wiki。一旦混了,几周以后再也分不清谁是谁。
- 不让「删除」和「排除」混淆——排除只是知识库不收纳,原文可以接着存在。这一条让我整理时轻松很多。
整理知识库的本质,是给材料划边界。
留什么、扔什么,不是审美问题,是「它有没有资格在未来代替源头回答问题」。能代替的就留;不能代替的当线索。线索可以散在工作目录里,知识必须能在 wiki 里独立成立。
我想要的不是更大的库,是下次进来还愿意打开的库。